Cloud security automation enables organizations to improve infrastructure visibility, enforce security controls, reduce the mean time to respond (MTTR) for security incidents, and speed up recovery. Security automation links various cloud security tools, enabling seamless integration and coordinated response across cloud environments.
When tools like AWS Security Hub or Azure Sentinel detect issues, automation ensures that these findings are properly tracked, remediated, and documented across multiple compliance frameworks. Automation platforms also streamline compliance with regulations like HIPAA, GDPR, and PCI DSS by automatically collecting evidence, updating documentation, and maintaining audit trails, all while reducing manual effort and potential gaps in security coverage.
This article describes best practices for cloud security orchestration and automation and includes specific practical examples.
Summary of cloud security automation best practices
Map cloud infrastructure
Maintaining a comprehensive list of assets ensures complete visibility into your cloud infrastructure and enables real-time detection of gaps or vulnerabilities. In dynamic cloud environments where changes occur frequently, this visibility becomes crucial for identifying and addressing security risks before they can be exploited.
Cloud infrastructure mapping can be broken down into four fundamental steps:
Perform continuous discovery: Enumerate resources across your environment in real-time.
Collect essential details: Gather relevant metadata, configuration, and access information for each resource.
Analyze and transform the data: Filter, normalize, and classify resource information for deeper insights.
Output the data: Deliver the processed data to dashboards, alerting systems, or subsequent security processes.
These fundamental steps provide a framework that can be applied to both persistent cloud resources, such as virtual machines and storage buckets, as well as ephemeral resources, like containers and serverless functions.
Tracking persistent resources
To demonstrate the four fundamental steps in action, let’s examine an automated workflow for discovering and tracking EC2 instances in AWS:
During the discovery phase, a webhook trigger invokes the AWS API to enumerate all EC2 instances across specified regions.
In the data collection phase, we gather essential metadata, such as security groups, IAM roles, and network configurations for each instance.
The analysis phase then processes this raw data, correlating instances with their associated resources and normalizing the information into a standardized format.
Finally, the processed data is integrated into security dashboards and monitoring tools, enabling continuous visibility and automated security assessments.
An example of this workflow, with each step highlighted, is provided below.
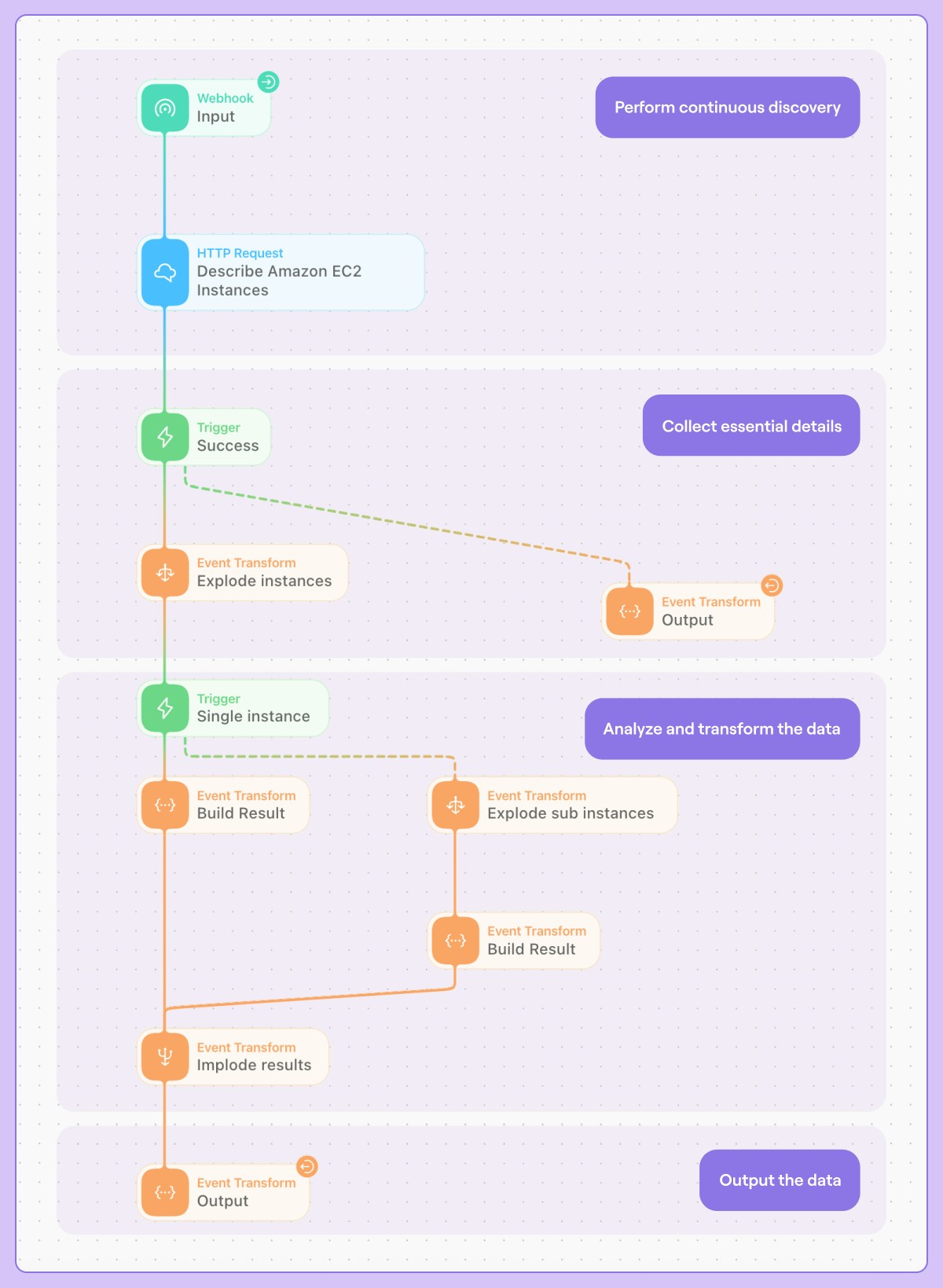
Enumerating EC2 instances in a given region (source)
Tracking ephemeral resources
Tracking persistent resources generally follows a straightforward process of discovery and monitoring. However, the dynamic nature of modern cloud environments presents extra challenges when managing short-lived resources. Dynamic resources such as containers, serverless functions, and auto-scaled instances may only exist for minutes or even seconds, which presents new challenges for achieving continuous security visibility.
Four of these challenges are outlined below, along with solutions.
Workflow orchestration and automation for security teams
- No code or low code - no custom development necessary
- Integrates with all your systems - internal and external
- Built-in safeguards like credential management and change control

Pitfalls to avoid
While the mapping strategies above provide a framework for tracking both persistent and ephemeral resources, organizations should be aware of several common challenges that can impact the effectiveness of their cloud infrastructure mapping efforts:
API rate limiting: When performing continuous discovery of resources, especially across large environments, improper API request handling can trigger service limits. Implement intelligent throttling, pagination, and request batching to maintain consistent scanning while respecting API quotas.
Resource overhead: While real-time tracking is crucial, overly aggressive polling of persistent resources or excessive event processing for ephemeral resources can lead to unnecessary costs and performance degradation. Balance monitoring frequency with operational requirements, using event-driven approaches where possible.
Stale data: The dynamic nature of cloud environments demands careful consideration of data freshness. Cached resource information must be regularly validated and updated, particularly for ephemeral resources where stale data could lead to security blind spots.
Missing context: As mentioned above in the discussion of resource correlation strategy, failing to maintain relationship data between resources can severely impact security analysis. Ensure that your mapping solution captures both direct and indirect dependencies between persistent and ephemeral resources.
Data normalization: When tracking resources across different services or cloud providers, inconsistent data formatting can create gaps in security analysis. Implement standardized data models that maintain consistent resource representation while preserving provider-specific security attributes.
Enforce security controls
Cloud security automation goes beyond automating mundane tasks: It can also enforce critical security controls, ensuring consistent compliance with internal policies, industry regulations, or accreditation requirements (like SOC 2, HIPAA, or PCI DSS). This ensures that a given standard is consistently and constantly enforced and reduces the need for manual interventions.
To see this in action, consider the template below, which demonstrates how to automate HIPAA compliance documentation using a service called Drata. Upon uploading training evidence to Drata, the system automatically updates personnel records and marks the associated control as compliant.


Add HIPAA training evidence to Drata
This automation Story hosts a web application to upload the HIPAA evidence in Drata. Once the file has been uploaded, it will run through the personnel with Drata to add the evidence to their account and mark the account as compliant with the control.
Tools
A workflow orchestration and automation platform such as Tines could further enhance this workflow. Here are a few examples:
For teams needing real-time status updates, configure alerts or notifications within Drata to confirm successful evidence uploads.
For larger organizations, integrate Drata’s API with your HR system to synchronize personnel records across multiple departments.
Use automated workflows within Drata to ensure that all relevant stakeholders are notified when compliance documentation changes.
This type of automation streamlines compliance management by reducing manual effort and human error, ensuring consistent documentation of policy requirements while freeing up valuable time for security teams to focus on more strategic initiatives.
See Tines’ library of pre-built workflows
Optimize alert triage
Cloud security teams are overwhelmed by alerts from multiple tools. Automating the alert handling process enables consistent evaluation and reduces analyst fatigue. To do this, use the two-step alert handling framework described in this section.
Alert ingestion
The first step is establishing an alert ingestion system capable of handling the high volume and variety of security alerts generated in cloud environments. This system must ensure that alerts are processed accurately and effectively, with allowance made for times when workloads are at their peak.
Although the exact system will be unique for each organization, there are several challenges that every alert ingestion system must account for. These are outlined below, along with some solutions.
Data enrichment
With an alert ingestion pipeline established, the next critical step is transforming these raw alerts into contextualized, actionable insights through systematic enrichment. Effective threat analysis requires additional context for accurate risk assessment and response prioritization. An enrichment pipeline must augment alerts while continuing to balance system performance and cost efficiency.
Methods to achieve this balance are outlined in the table below.
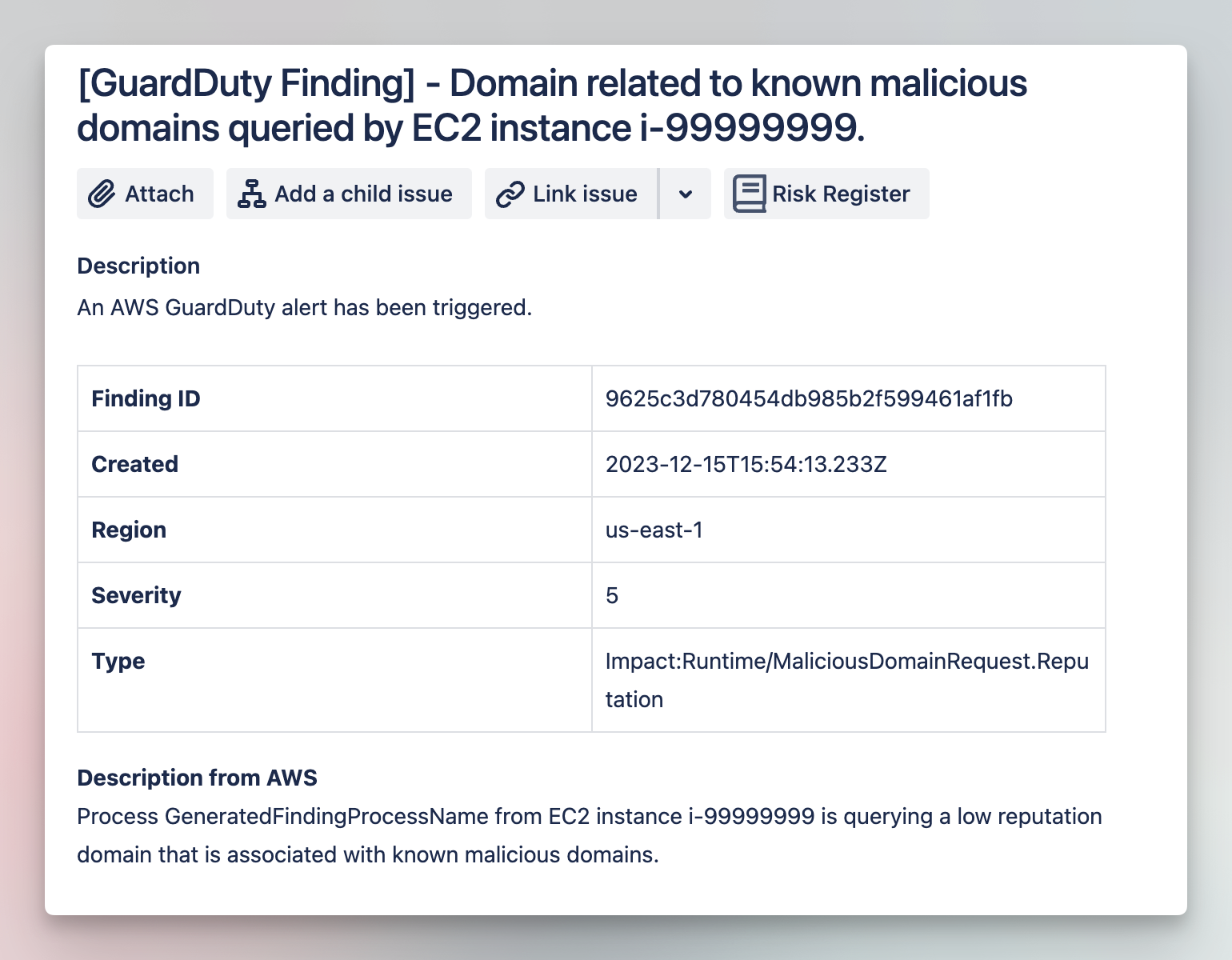
To see these steps in action, consider the example workflow below. This workflow ingests AWS SNS for AWS GuardDuty alerts, enriches them with contextual information, and then inserts them into JIRA. Each step is managed through a separate workflow orchestration and automation platform, which helps to manage the cost.


Track AWS GuardDuty alerts in Jira and remediate
Enrich AWS alerts with more context using GuardDuty, then take action to isolate new connections, lock attackers down, review credential usage, or re-apply restrictions, all while managing a case in Jira with this Story.
Tools
Pitfalls to avoid
When optimizing alert triage, there are two common pitfalls to avoid, in these areas:
Alert volume management: During security incidents, a surge of related alerts can overwhelm enrichment APIs and processing queues, potentially causing critical alerts to be delayed or missed. Implement alert prioritization based on asset criticality and issue severity to ensure that high-priority security signals receive immediate attention.
Triage health monitoring: Failing to monitor the triage system itself can result in undetected failures in alert processing, creating dangerous blind spots in security coverage. Implement health checks and performance monitoring across the entire alert lifecycle to maintain complete security coverage.
Enable auto-remediation
After optimizing alert triage and enrichment, the next step is implementing automated response capabilities to resolve straightforward security issues while routing complex cases for human analysis. The framework presented in this section provides a pathway to do this.
Priority-based remediation
Start by implementing a priority management system that orchestrates remediation actions based on alert severity and resource criticality. This helps the system manage peak workloads by prioritizing the items that matter right now vs those items that can be queued for later.
Do this by implementing solutions in the following areas:
Severity-based prioritization: Implement dynamic queue prioritization using weighted scoring that considers alert severity, asset criticality, and threat context. Configure remediation workers to process high-priority queues first while maintaining separate queues for different severity levels to prevent low-priority fixes from blocking critical remediations. For example, critical production security group misconfigurations should be prioritized over non-urgent tag compliance issues.
Resource-based queuing: Implement a resource-specific queuing system to serialize remediation actions for each target asset or resource group. For example, when patching an ECS service, ensure that dependent task definitions and container images are updated first. Maintain a locking mechanism using services like DynamoDB to track in-progress remediations and prevent conflicting changes.
Concurrent remediation requests: Build a scalable system that processes multiple remediation requests in parallel while respecting resource constraints. For example, set up auto-scaling Lambda functions that process multiple remediation requests in parallel while respecting AWS service quotas and API limits.
Staged rollout mechanisms
Once a priority management system has been implemented, ensure an effective rollout mechanism method is used. This safeguards the overall environment while continuing to improve auto-remediation.
In the table below, several rollout mechanisms are presented. Choose one or more of the methods to suit your organization.
State management
Even with carefully designed rollout strategies, remediation workflows can encounter unexpected failures. Maintaining state management is essential for tracking progress, handling failures gracefully, and maintaining system reliability.
Use the table below to implement effective state management.
Human-in-the-loop decision-making
Define where and when humans should be included in any decision-making. This should consider factors such as the system's authority to act, who the decision-maker should be, and how to queue the event while waiting for the decision.
Use the table below to capture these requirements:
Pitfalls to avoid
The table below shows pitfalls to watch for while implementing auto-remediation and suggested solutions and best practices.
Plan for resource recovery
Automated recovery workflows provide rapid restoration in the event of a cloud resource compromise or failure. When implemented effectively, these workflows allow customer-facing services to minimize downtime while quarantining assets and resources for further investigation.
For example, consider an EC2 instance exhibiting potentially suspicious behavior. Using an automated workflow, an organization can:
Capture the relevant details of the instance for further investigation by SOC or CSIRT resources.
Provision a new resource to ensure service availability.
Trigger further automated remediation actions if necessary.
Use the steps below to plan for resource recovery:
Map detection and triggering workflows: Map out how an alert detection triggers an automated response. This should include how your detection framework passes enriched alerts into the relevant response workflow or orchestration.
Plan for forensic capture: Before replacing an impacted resource, capture a snapshot or backup for forensic analysis and future reference. This snapshot should be securely stored and protected from unauthorized access. Note that the type of snapshot (e.g., crash-consistent or application-consistent) depends on the application’s nature and must be decided on before implementation.


Create snapshot and isolate a compromised AWS instance
Isolate and take a snapshot of an AWS EC2 instance that might be compromised. This can allow for forensic investigation to be performed while quarantining the host.
Tools
Created by
3. Create resource provisioning images: New resources are provisioned from an approved baseline image or backup. This baseline should be regularly updated and patched to minimize vulnerabilities. Use infrastructure-as-code (IaC) tools such as Terraform or CloudFormation to automate this process and ensure consistency.
4. Store configuration restoration information: Ensure that relevant configurations—including networking (e.g., security groups, network interfaces), security policies (e.g., IAM roles, access control lists), and application configurations—are stored automatically. These configurations are then applied to the restored resource. Configuration management tools such as Ansible, Chef, or Puppet can be used to automate this process.
5. Include validation and decommissioning: Use automated checks to validate the integrity and functionality of replacement resources. This can include services such as health checks, integration tests, and security scans. Once validated, securely decommission the compromised resource, including data wiping where necessary.
Watch out for these pitfalls when planning for resource recovery:
Ignoring dependencies: Cloud applications often have complex dependencies between resources. Failing to account for these dependencies in the recovery workflow can lead to incomplete or failed recovery.
Lack of version control and IaC: Without version control and IaC and configurations, it’s difficult to track changes and revert to previous states if necessary.
Cost optimization: Consider the cost implications of automated recovery, such as storage costs for backups and compute costs for provisioning new resources. Optimize the workflow to minimize costs without compromising recovery objectives.
Failure to address the root cause: Automated recovery restores functionality, but it doesn’t address the root cause of the incident. Implement post-incident analysis to identify and address the underlying issue to prevent future occurrences.
Incomplete logging and forensics: Skipping thorough logging or snapshot creation can hamper post-incident investigations and root-cause analysis.
Lack of testing: Failure to regularly test recovery workflows may result in misconfigurations or unnoticed errors.
Organizations can significantly improve their resilience and minimize the impact of security incidents and operational failures in the cloud by addressing pitfalls and implementing a well-designed automated recovery strategy.
Did you know Tines' Community Edition is free forever?
- No code or low code - no custom development necessary
- Integrates with all your systems - internal and external
- Built-in safeguards like credential management and change control
Last thoughts
Cloud security automation is no longer optional in today’s threat landscape. For security professionals, the benefits are clear: it eliminates repetitive tasks, reduces human error, and enables rapid response to threats at cloud scale. However, managing cloud security presents unique challenges: ephemeral resources that spin up and down, IAM permissions that need constant adjustment, and alert volumes that overwhelm traditional response processes.
Orchestration and automation platforms like Tines significantly simplify creating and managing complex security workflows. By offering a plug-and-play approach, these platforms eliminate the need for engineers to deploy and maintain separate automation services or develop intricate custom systems. This streamlined approach empowers security teams to rapidly build and deploy sophisticated automation without requiring extensive coding expertise.