On the one hand, automated incident response offers various benefits, such as reducing the mean time to response and resolution and the ability to scale solutions to match an organization’s infrastructure and avoid dependency on “tribal knowledge.” On the other hand, automated incident response presents several quandaries exemplified by questions such as these:
Which processes should be automated first?
What is the appropriate balance between autonomous decision-making and human-in-the-loop decision-making?
Which parts of an organization’s infrastructure should be included in the automation?
These questions don’t have standard answers, which makes matters even more complicated. Each organization operates under a unique set of constraints and requirements, and there are multiple ways to design an automated incident response solution.
This article provides six best practices to help organizations decompose the steps for planning an incident response automation program suitable for their needs. It helps them create a repeatable methodology for identifying security management workflows and incrementally automating them based on the interests and preferences of the stakeholders involved.
Summary of best practices for implementing automated incident response
Define the scope and identify the stakeholders
Automated incident response requires coordination between multiple teams and decision-makers (stakeholders). Each stakeholder holds specific responsibilities and owns a distinct part of capability delivery. Understanding these requirements, combining them with the proposed outcomes, and defining areas of responsibility provide the basis for the project's scope.
For example, service availability teams frequently have infrastructure uptime targets and use automated scaling and load-balancing to achieve them. If a proposed automated incident response action automatically quarantines part of the infrastructure under their administrative control, that team would need to be involved.
Similarly, stakeholders have different perspectives on automated incident response. Some may desire a system that eliminates human-in-the-loop decision-making. In contrast, others may wish to ensure that humans make the decisions and trigger only discrete automated procedures.
Establishing the scope identifies these areas of alignment and conflict and the stakeholders who will be impacted.
Here are some recommendations and resources to start this process.
Infrastructure mapping considerations
Automated incident response relies heavily on accurate application dependency mapping. ADM simply means identifying the assets that support a particular business application, such as network devices, databases, web servers, virtual machines, and containers. Such an asset inventory helps connect detected events to specific assets and business applications to plan corresponding actions. For example, if a database is compromised, knowing if it supports a mission-critical application or an isolated lab environment is important before taking action.
When implementing automated incident response, try to start with application environments with clear mapping of assets and applications—or application environments small enough that identifying assets would be a simple task. If a well-mapped environment is unavailable, it’s worth expanding the project’s scope first to gather an asset inventory.
Workflow orchestration and automation for security teams
- No code or low code - no custom development necessary
- Integrates with all your systems - internal and external
- Built-in safeguards like credential management and change control

Start with a single environment
If multiple well-mapped environments are available, select one to begin with. Use this environment to navigate the entire scoping process.
When choosing an environment, look for one with interested stakeholders, clearly defined infrastructure, and an openness to adding new features. The upfront planning will simplify the implementation process and help build interest and excitement throughout the organization once the initial well-defined project achieves positive results.
Propose a list of automated processes
After selecting an environment, create a list of potential automated actions. These actions form the basis of an automated incident response capability and will help frame the implementation strategy.
The proposed list of automated actions should be comprehensive enough to demonstrate the effectiveness of an automated incident response approach while also showcasing an organization's strengths. For instance, automating network packet capture analysis would be impossible if an organization did not capture raw packet data.
The team at Tines has created the “SOC Automation Capability Matrix,” which is available at this publicly accessible link (here). This page lists security operations center (SOC) processes and aligns them with orchestrations and automation workflows. To use this page, click the link and locate a process matching the targeted environment. Next, click on the selected process to view a list of pre-developed orchestrations available in the Tines library. You can use these orchestrations as they are or edit them as needed.
For instance, if phishing alerts are a high priority for automation, you could:
Navigate to the SOC Automation Capability Matrix page.
Choose the Phishing Alerts and Reports table.
Review the Description and Techniques sections to make sure that this information matches your expectations.
Choose an existing automation from the list of examples provided.
Edit the chosen example as needed to match your infrastructure.

Selecting a process, reviewing the techniques, and choosing an example within the SOC Automation Capability Matrix (source)
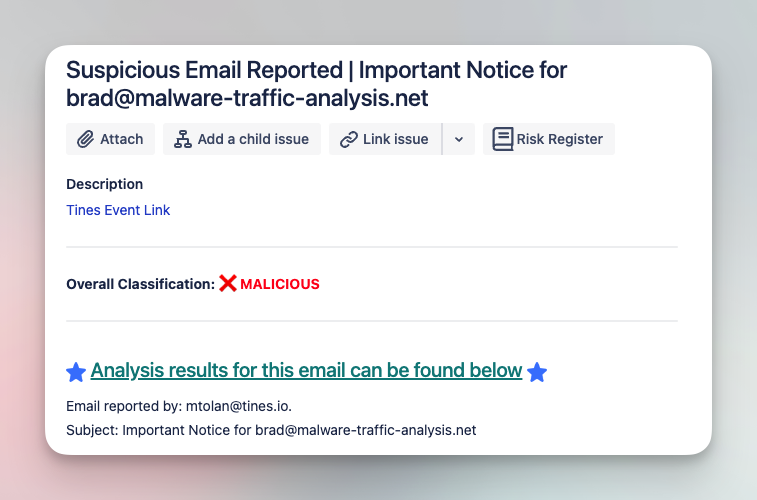
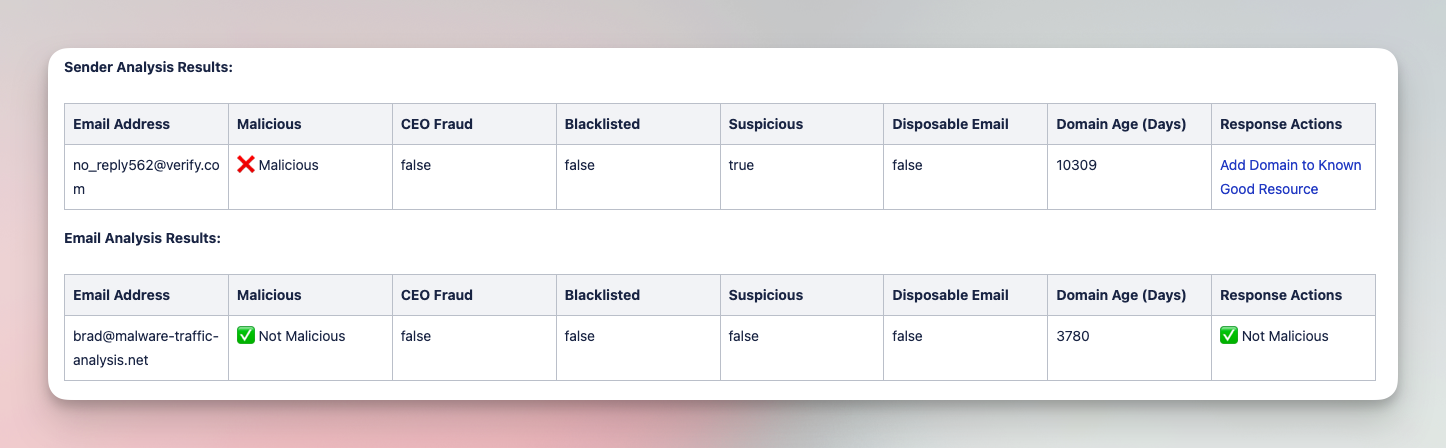
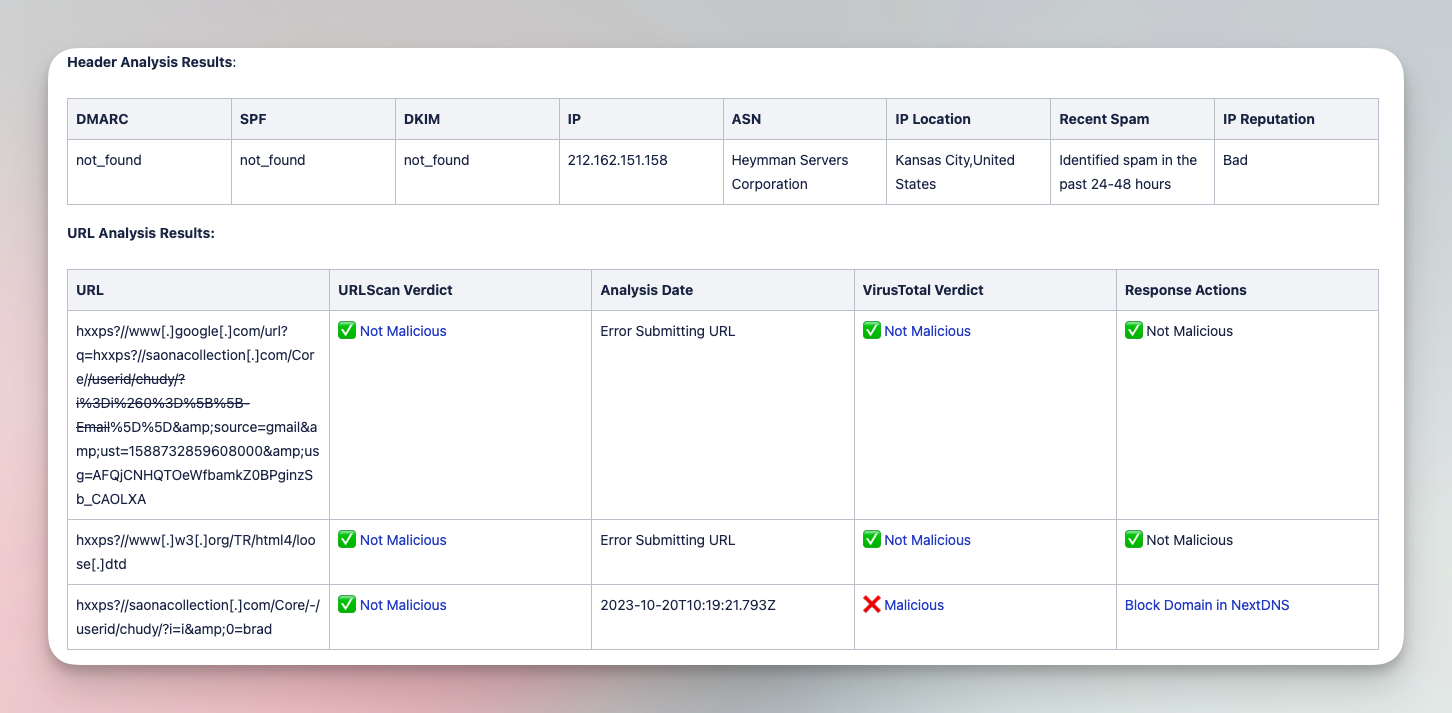
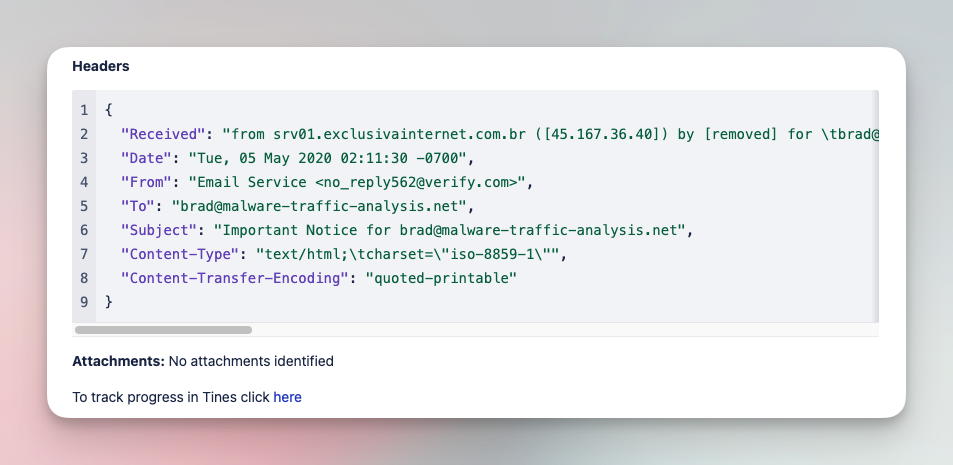
The following workflow is an example of the types of workflows available in the SOC Automation Capability Matrix. In this case, the workflow covers the analysis and triage of suspicious emails:

Analyze and triage suspicious emails with various tools
Submit suspicious emails and investigate with a comprehensive analysis of files, URLs, and headers. Add IOCs to various tool blocklists in order to limit impact of phishing campaigns.
Tools
CrowdStrike, EmailRep, Jira Software, NextDNS, URLScan.io, VirusTotal
Created by
Map proposed actions to impacted stakeholders
With an environment selected and a list of proposed actions available, map the proposed actions against assets and stakeholders. This creates a high-level stakeholder and asset list, which can be added to the scoping process.
The table below provides a simple way to perform this mapping. It lists the proposed actions, each having one row. Each action is associated with the assets that will be impacted and the stakeholders responsible for these assets.
Using a deliberately simplistic list of three proposed actions, the table immediately identifies the impacted assets (web servers, AWS infrastructure, and all employee devices) and the impacted stakeholders (infrastructure, engineering, development, and sales teams). The affected stakeholders and assets can now be added to the project's scope, and discussions can be initiated. Note that the examples in the table below have deliberately truncated the list of impacted stakeholders for readability. For most organizations, the list of impacted stakeholders would be significantly larger.
Develop an implementation plan
When planning the implementation of an automated incident response capability, use a crawl, walk, run approach. This minimizes disruption to existing infrastructure while allowing stakeholders to build confidence in the automated system.
Crawl stage
In this first stage, automate the existing manual tasks. Focus on identifying the differences between an automated approach and the existing manual approach and invest time updating impacted tools and processes.
For instance, imagine if a malicious IP address alert is qualified by manually checking the SIEM for any connections to this IP address in the last 30 days. This is a great candidate for automation, as it is a highly repeatable process with an existing manual playbook.
The implementation plan should allow time for this automation to be tested and developed and for SOC playbooks to be updated.
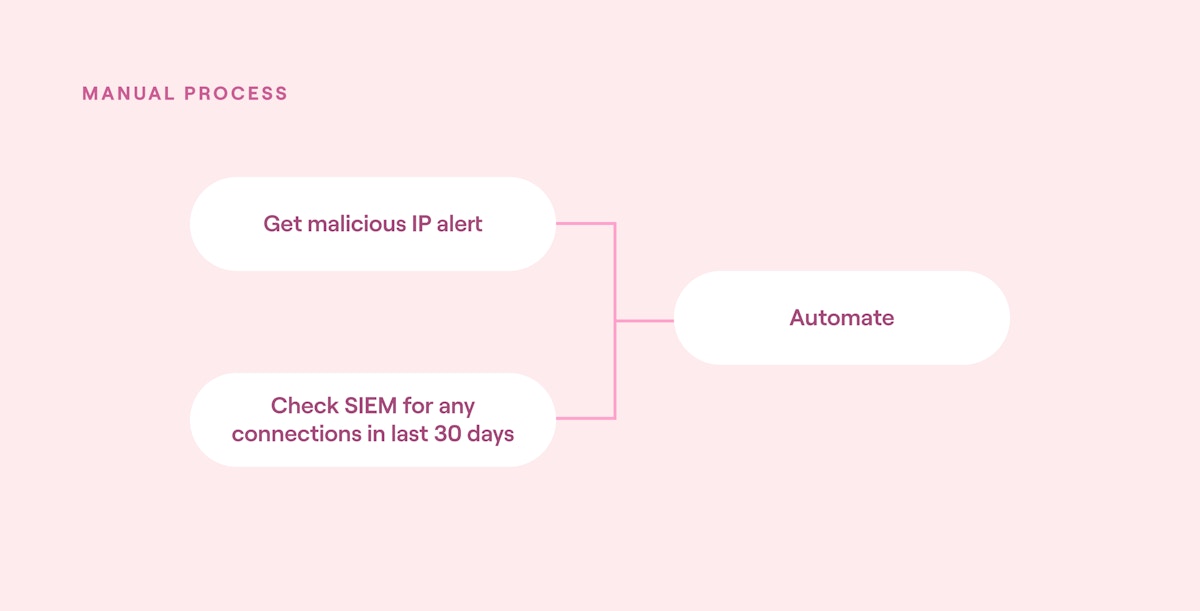
Crawl stage automation block diagram (source)
Walk stage
In this stage, the processes from the crawl stage are combined into more complex orchestrations. This allows the automated incident response system to start making decisions about handling certain alerts without requiring human-in-the-loop decision-making.
For example, imagine if the previous malicious IP address alert was updated so that SOC operators are only passed qualified alerts, meaning only alerts with confirmed connections to the malicious IP. In this instance, the automation would need to be updated with branching logic to handle each option (connection or no connection), along with how to resolve non-qualified alerts.
The implementation plan should allow time for each branch of this logic to be tested and for updating the SOC playbooks. It should also allow time to discuss practical considerations for non-qualified alerts, such as routine reviews.
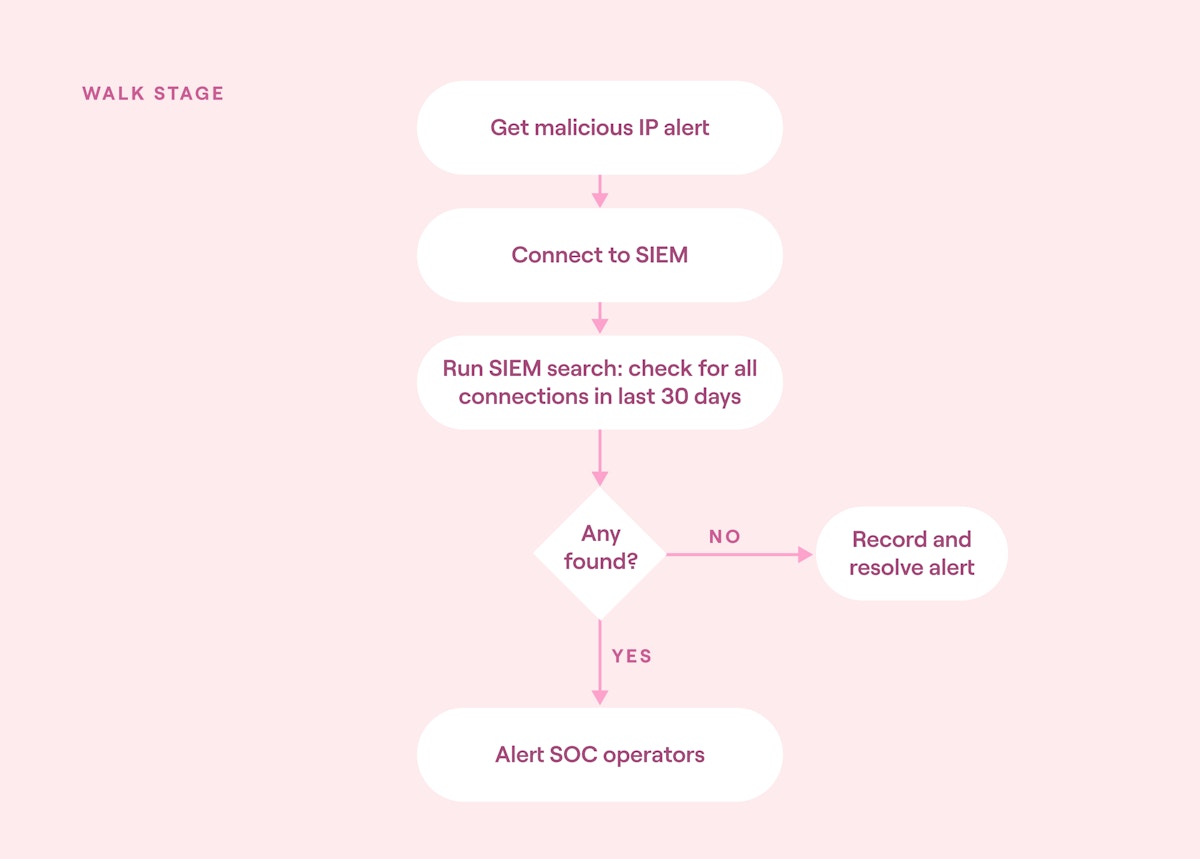
Walk stage automation block diagram (source)
Run stage
In this stage, combine the learning outcomes from the previous two stages into a repeatable process. This allows the automated incident response system to add more and more value to the organization while minimizing the chance of negative outcomes.
For instance, building on the previous example, a series of analysis processes for malicious IP address connections could be identified. This might include analyzing connection ports being used or correlating with threat intelligence tools. Each process could be automated and combined into a progressively more complex orchestration framework.
As before, when a new automation is developed, the implementation plan should allow time to update existing tools, processes, and stakeholders. The example below from the Tines library shows the resulting automated incident response workflow.


Triage Elastic Security alerts and block malicious IPs
Analyze Elastic Security alerts using GreyNoise and block malicious IP addresses. Check which patches were installed and build a case with all of the results, while keeping key stakeholders informed.
The human-in-the-loop consideration
When discussing automated decision-making, the question of when humans should be involved typically arises. As the complexity of the proposed automation and orchestration increases, this question will likely be debated at length.
While no “right” answer suits every organization, the appropriate level of human involvement can be collaboratively determined based on experiments. This can be done by allowing time to experiment with varying levels of automation without formally replacing the existing manual processes. In other words, the automated outcomes would be simulated and documented but not enacted. As the team gains more confidence in the automation's results, the autonomy level can be gradually increased to meet stakeholder preferences.
Automate alert enrichment and correlation
Automated incident response requires high-quality enriched alerts. These alerts form the foundation of all subsequent actions and frequently determine the success or failure of an automated incident response capability.
Four aspects for automating alert enrichment and correlation are detailed below.
See Tines' library of pre-built workflows
Alert validation
Alert validation improves an organization's alert confidence level by using correlating information to confirm or deny the relevance of a specific event. In turn, this ensures that the automation system only receives alerts that are significantly more likely to be valid.
To illustrate a qualified alert, consider the “walk” stage from the previous section. In this example, an alerting system receives a notification about a generic malicious IP address. When the alert is triggered, it is unclear whether this alert is relevant to the organization—it simply identifies a “bad” IP address. Assuming there is no doubt regarding the malicious nature of the IP address, most organizations would want to investigate this alert further.
However, in this scenario, the automation platform conducts an initial validation before escalating the alert. It establishes if the alert is relevant to the organization by:
Checking if there have been network connections from an organization's assets to the malicious IP address.
Discarding malicious IP address alerts if no connections from an organization have been observed; i.e., the IP may be malicious, but no one in the organization has connected to it anyway.
Escalating only those malicious IP address alerts where a network connection has been made from an asset within the organization.
Only when the alert has been validated is it passed on for further action.
Alert enrichment
Once an alert has been validated, it should be enriched with information about the people and assets impacted. This helps narrow down the next steps and provides clear, discrete information for follow-up processes.
Typically, this information should include:
The asset or assets impacted
The person or persons impacted
Any relevant historical information
For instance, if a qualified alert about a malicious process on an employee laptop asset is received, some enriched information should include:
The name of the asset
What time the malicious process started and stopped
What time the employee logged in and logged off
Whether any other logins to that asset were observed before, during, or after the malicious process activity
Any network connections from the employee's laptop
Did you know the Tines community edition is free forever?
Additional alert enrichment considerations
The process of enriching alerts often highlights gaps in an organization's monitoring and recording systems. Additional monitoring or more effective recording is often necessary, especially in cloud environments where ephemeral containers and Lambda functions are more prevalent.
Two approaches can be used to help navigate these gaps without disrupting the implementation of automated incident response, outlined below:
Confidence ratings
Consider this scenario: You have a threat intelligence feed that is very effective at identifying edge case indicators of compromise (IOCs). However, it can be unreliable for more general threat intelligence information. You definitely want to keep it because of its edge case capability but need to manage the unreliability factor.
To do this, you confirm any IOCs from this tool by combining the output from other threat intelligence tools using the following rules:
If three or more providers confirm the IOCs, proceed with an incident response approach
If less than two providers confirm the IOCs, discard the alert
If only two providers confirm the IOCs, send them to a senior analyst for assessment
Use confidence ratings to convert this scenario into an automated incident response approach. Confidence ratings assign events a numeric score, where a higher score indicates greater confidence in the event's validity.
For instance, assuming that you use four threat intelligence feeds for this scenario, the confidence ratings could be:
If the score less than 66.6% is received (i.e., fewer than two confirmations), discard the alert.
If the score is between 66.6% and 100% (i.e., two confirmations), send it to a human SOC operator for further analysis.
If the score of 100% is received (i.e., three confirmations), respond automatically.
Converted into a block diagram, this would look like the following:
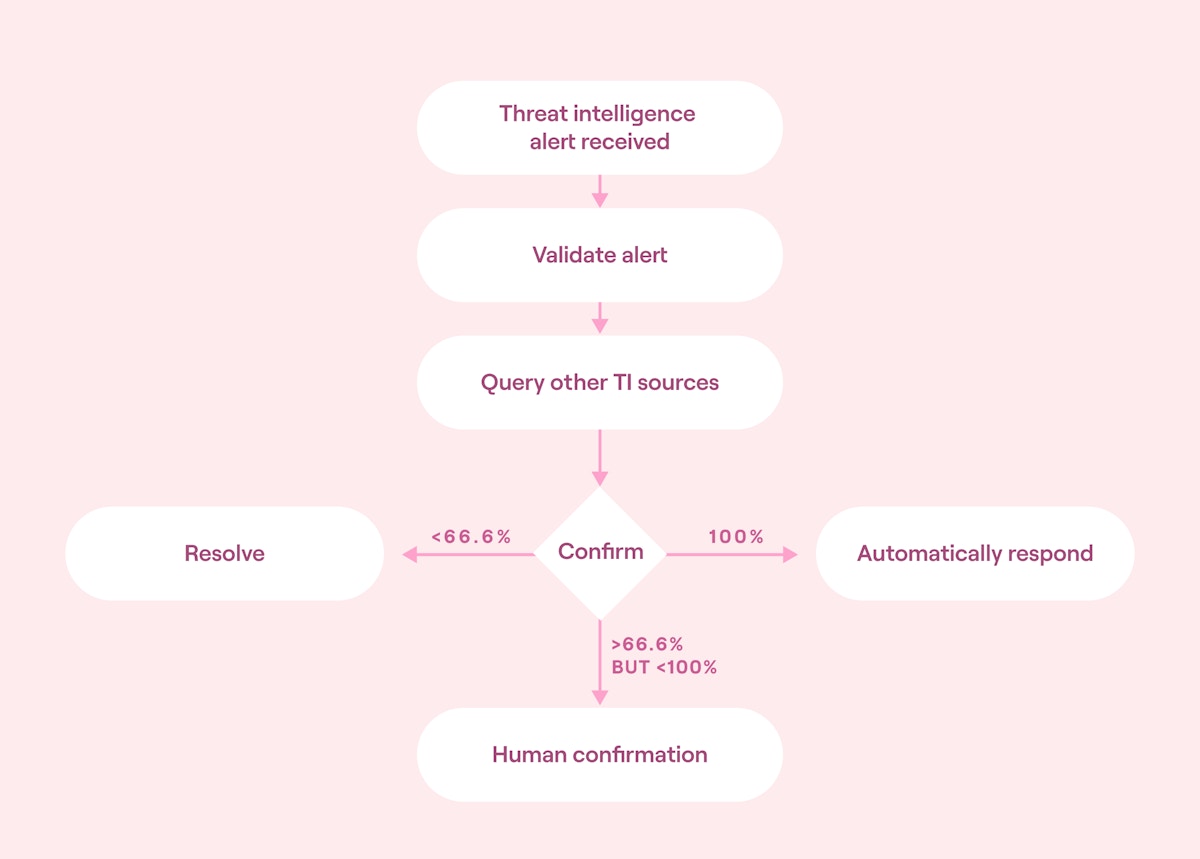
Automated incident response using a confidence level (source)
Standardize investigation workflows
Automating incident response actions requires clear steps with discrete, measurable outcomes. This ensures that any actions taken are predictable and measurable and do not exceed the intent of the response action.
To achieve this, break down each response action into distinct steps that can be chained together. For instance, consider the response action of taking a memory dump on an employee laptop in response to an alert. To achieve this, a manual process might look like this:
Connect to the employee's laptop.
Make sure the memory dump tool is on the endpoint.
Run the command to dump memory.
Remove the memory dump tool.
Additional work is needed to transform this into an automated response action. First, the specific tool used to take the memory dump must be identified. Next, it is important to determine the steps to take if the tool encounters a failure. Finally, a method for informing the incident responder after the action has been completed should be established.
The workflow below, built using the Tines workflow orchestration and automation platform, demonstrates what this might look like in action.

Initiate CrowdStrike RTR memory dump
Initiate a remote Memory Dump in CrowdStrike Falcon via a Tines form. Input a device ID and a filepath on the remote machine and receive an email once the memory dump has completed on the device.
Tools
Capture all automated response actions
Ensure that all automated incident response actions are captured at the time of the action. This should include enough detail to fully reconstruct an incident response action from the initial event through to the resolution, analyze if the response action was sufficient, and ensure that the actions taken were appropriate.
For instance, in the memory dump example from the previous section, the following information should be captured:
The alert that triggered the initial memory dump requirement
Which laptop (asset) was connected to
What commands were run by which tool
The outcome of the command
When the session was ended
The information should be stored in an organization's case management system and be regularly reviewed for compliance and effectiveness.
Provide appropriate access to monitored environments
There is nothing more disruptive for incident responders than being prepared to take a specific response action only to discover that they lack the necessary access privileges to execute their plan. It can be incredibly frustrating to spend crucial hours waiting for the team responsible for providing access to be paged in, explaining the situation, and finally receiving the required permissions.
Avoiding this issue is even more critical for automated incident response, where response times are measured in minutes and seconds rather than hours.
To prevent this issue from occurring, make sure these processes are in place.
Read our free essential guide to security automation
Closing thoughts
Automated incident response is a powerful way for organizations to reduce their mean time to respond and mean time to resolution. However, implementing it introduces significant complexity.
Organizations should use the six best practices provided in this article to identify and simplify this complexity. Doing so enables them to leverage the power of automated incident response while minimizing the chance of things going wrong.