

In this blog post, Tines software engineer Shayon Mukherjee shares how lessons from a recent incident led to improved platform resilience and more comprehensive testing practices.
It was a typical late June afternoon when we embarked on what seemed a routine Redis cluster upgrade across approximately 40 customer stacks. The upgrade was essential, influenced by a previous outage that highlighted the risks of not using more robust instances and better networking support on those instance types.
This wasn't the first time we performed such an upgrade, nor is it going to be the last time. But little did we know that this upgrade would soon reveal an unseen issue that lay dormant, undetected, and ready to teach us a valuable lesson.
A few moments into the upgrade process, our monitoring systems flagged the Toolkit API Down alarm. Tines Toolkit is a Tines response-enabled webhooks-powered service. This alert was the first signal of something amiss. The webhooks were timing out, affecting crucial customer workflows. The immediate response was swift - our engineers triggered a force deployment to flush out any bad state from our containers, bringing things back online within a few minutes. But this was just the beginning. Now we needed to understand what had actually happened.
How does it all work?
In our system, response-enabled webhooks play a critical role, especially in how they interact with Redis Pub/Sub to manage real-time data flows. Before we dive further into the bug, let's take a quick minute to understand the system first.
Our application is built using Ruby on Rails, with Puma as our web server and Rack as the web server interface. For response-enabled webhooks, we use a technique known as Socket Hijacking to make async webhooks function like synchronous ones.
When a webhook request is received, Rack performs what's known as “Full Socket Hijacking.” This process closes the Rails response object, which frees up the request handling thread (inside Puma) to return to the pool of available workers while maintaining the socket connection to the client. This allows the Puma server to accept new web requests without blocking the response for the synchronous webhook, all the while keeping the socket connection open with the client to return a response once it is available.
Another important part of this system is a simple Redis Pub/Sub implementation running from a dedicated listener thread inside the web server. When a webhook is received, we enqueue the relevant Tines Action Run and open a Redis subscription (from the thread) to listen for the event received when the Tines story exit action generates the response. We then proxy it back to the client.
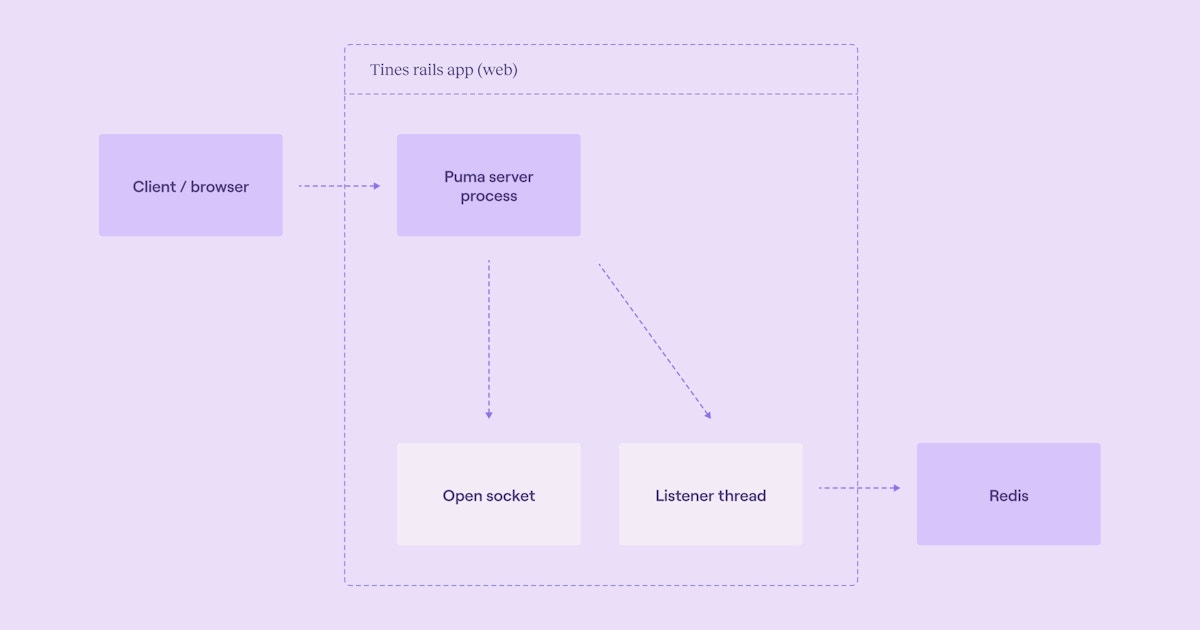
The hidden bug
Normally, this dedicated listener thread maintains a persistent connection with Redis to receive and process messages. However, during the upgrade, it encountered connectivity issues, and without any system alerts or logs, the Redis persistent connection died. This failure is one of those classic cases of "the server is running but nothing is working,” just a quiet stoppage that gradually led to service degradation as new webhook requests could no longer be processed.
It took us a while to reach this conclusion. It required an examination of logs, reading the code, formulating hypotheses, and running some controlled failure cases. We were eventually able to recreate the scenario both locally and in production, and felt confident that this failure mode was the primary contributing factor to the incident.
This incident highlighted something in our system’s architecture: a lack of a good error handling or recovery mechanism for the webhook's listener thread during Redis connectivity or similar issues.
This oversight meant that a single point of failure could lead to disruptions in our production environment, a lesson that was both surprising and invaluable for our ongoing efforts to build a more resilient platform.
Lessons from the incident
This incident, albeit stressful, was a blessing in disguise. It exposed a critical vulnerability in how our webhook system was designed. The reliance on a single listener thread without a robust fail open mechanism was something that we had overlooked. But thanks to this incident, it was brought to light under circumstances that allowed us to respond without major consequences.
We learned that our preparations for zero-downtime capabilities during Redis updates were incomplete. We had not considered response-enabled webhooks in our chaos testing scenarios. This incident was a good reminder of the importance of comprehensive testing and the need for a holistic view of system dependencies and resilience, particularly for non-traditional parts of our system that might not be well-understood.
Embracing the incident
Incidents happen to everyone, but how you deal with them and learn from them is what counts. What stands out about incidents like these is not just the immediate impact or the technical breakdowns but the invaluable insight they provide into our systems.
Each incident, especially one that uncovers fundamental flaws, is an opportunity to improve, harden our systems, and ensure better service for our users.
They push us to think creatively about solutions and to fortify areas we hadn't even considered before.
Action items
While we’re happy that our automated monitoring caught the issue and we were able to mitigate the incident in a very short period, we still want to strive for more. We’ve already ensured the singleton thread acts in a reconciliation loop so that it can withstand similar issues in the future.
We’re committed to improving our resilience across the board. To achieve this, we’ll be conducting periodic and controlled chaos testing, which will include actions like taking down both our primary and ephemeral data stores to ensure that critical Tines workflows remain unaffected. This process should not only allow us to uncover more hidden unknowns like the ones we saw above but also catch regressions in our tooling and practices as we scale.
Reflecting on the incident
As we continue to build and maintain complex software systems, incidents like these are not just inevitable, they’re necessary.
They teach us about our systems' resilience, the effectiveness of our responses, and the areas that need more attention. They force us to confront the realities of our designs and our decisions.
So, in a way, we should be thankful for each incident. After all, each one gives us a chance to be better than we were the day before. Let's be thankful for these incidents - they are, indeed, our best friends in the ever-evolving landscape of complex systems.